
Vibe-coding a Japanese Language Partner
AI AI Tooling AI Workflow Conversational AI Cursor Next.js Vibe codingIntroduction
It’s been six years since I first visited Japan. What started as a 3-month work trip ended as an 18-month engagement and a cherished chapter of my life. By the time I left, my Japanese had barely progressed beyond the most basic level. I felt comfortable navigating the city and handling simple life tasks, such as grocery shopping and making reservations, without issue, but wasn’t as comfortable attempting small talk when opportunities arose.
As you’d probably expect, what little Japanese I had mastered rapidly deteriorated once I returned to Canada, and it’s only recently, in anticipation of another visit, that I’ve seriously resumed my studies. I’m currently taking private lessons with a tutor twice a week, and now, 2 months in, I’m starting to feel my comfort returning. However, being in Canada still doesn’t present an immersive environment and the same opportunities to stay engaged in the language.
That’s why I decided to build an AI-powered proof-of-concept conversational prototype to help me practice my Japanese outside of my lessons.
So Why Build It?
I tried Duolingo. Textbooks, Anki decks, Pimsleur, and many other apps. They all fell short in the skill I’m most focused on improving: conversation.
My goal was simple: to create a lightweight conversation partner that bridges the gap between my Japanese lessons. This proof of concept (POC) needed to:
- Capture voice input and convert it into text
- Generate conversational responses tailored specifically to JLPT N5 vocabulary and grammar
- Store a simple history of interactions
I explicitly avoided adding features that weren’t necessary for the POC, such as authentication, streaming audio, or security measures to keep the scope minimal and focused. Before investing in building a more robust solution, the goal of the POC was to measure:
- feasibility of the approach
- accuracy of the transcription
- relevancy of the generated conversational replies
Tech Stack & Architecture
- Frontend: Next.js with MediaRecorder API for audio capture
- Backend Integration: Google Speech-to-Text API for voice transcription
- Conversational Responses: OpenAI’s LLM with tailored prompts for JLPT N5
- Local State: Simple conversation history stored locally
The high-level user flow:
[Voice Input] → [MediaRecorder] → [Google STT] → [OpenAI API] → [Text Response] → [Google TTS] → [Chat history]Leveraging AI to Plan and Build
Lately, I’ve been having fun experimenting with different Cursor workflows and decided to use a modified version of Ryan Carson’s ai-dev-tasks rules to drive the vibe-coding sessions. Using ChatGPT, I put together two documents. A one-page product spec that outlined the desired tech stack and success criteria, and a project overview that outlined the high-level objective of the POC and broke down the key components of a solution. I added both of these documents to the agent context when using the create-prd and generate-tasks Cursor rules to generate a Product Requirements Document (PRD) and a structured task list.
Here’s an example snippet from the generated PRD:
## 3. User Stories
- **As a solo learner studying for the JLPT N5 exam,** I want to practice basic introductions and greetings so that I can feel confident in simple social situations.
- **As a beginner Japanese student,** I want to have short, simple conversations about daily topics (like weather, hobbies, food) so that I can reinforce my N5 vocabulary.
- **As a user who makes frequent grammar mistakes,** I want the application to provide simple, clear corrections so that I can learn from my errors without feeling discouraged.What Worked and What Didn’t
What Worked
Cursor’s AI-generated task list accelerated development significantly
I didn’t write any code myself. It took roughly an hour or two total to “pair” with the Cursor agent and work through the generated task list. After completing each set of tasks, I’d begin a new chat thread to refresh context, minimize hallucinations, and maintain the agent’s focus. These intervals were natural points to perform code reviews, occasionally resetting changes and prompting the agent again to address any concerns or suggest improvements. Once satisfied with the outcome, I’d commit the code and continue with the remaining tasks.
Google Speech-to-Text offered pretty good Japanese transcription
After many failed attempts at using ChatGPT’s voice mode to practice my Japanese, Google’s speech models felt like my first sip of Strong Zero after a humid Tokyo summer day. I was impressed by the accuracy of Google’s model when using audio from my dedicated microphone (Shure SM7B). The cursor agent defaulted to using the latest_long model identifier from Google’s STT API, although I’m not entirely sure the exact model it represents at the time of writing. The transcription was accurate when I used a dedicated microphone, but the initial testing experience done using my wireless earbuds and MacBook microphone was terrible. For example, “Hai, genki desu” became “Hi kinky. Guess”. Brutal. I’m well aware I don’t have a flawless accent and may stumble over some sounds when attempting more phonetically complex words, but I almost scrapped the project until I realized it was just an issue on my end. As this was a key pain point I had hoped to resolve from my ChatGPT experience due, to those models hallucinating even the most basic phrases, it was nice to see the POC validate this solution.
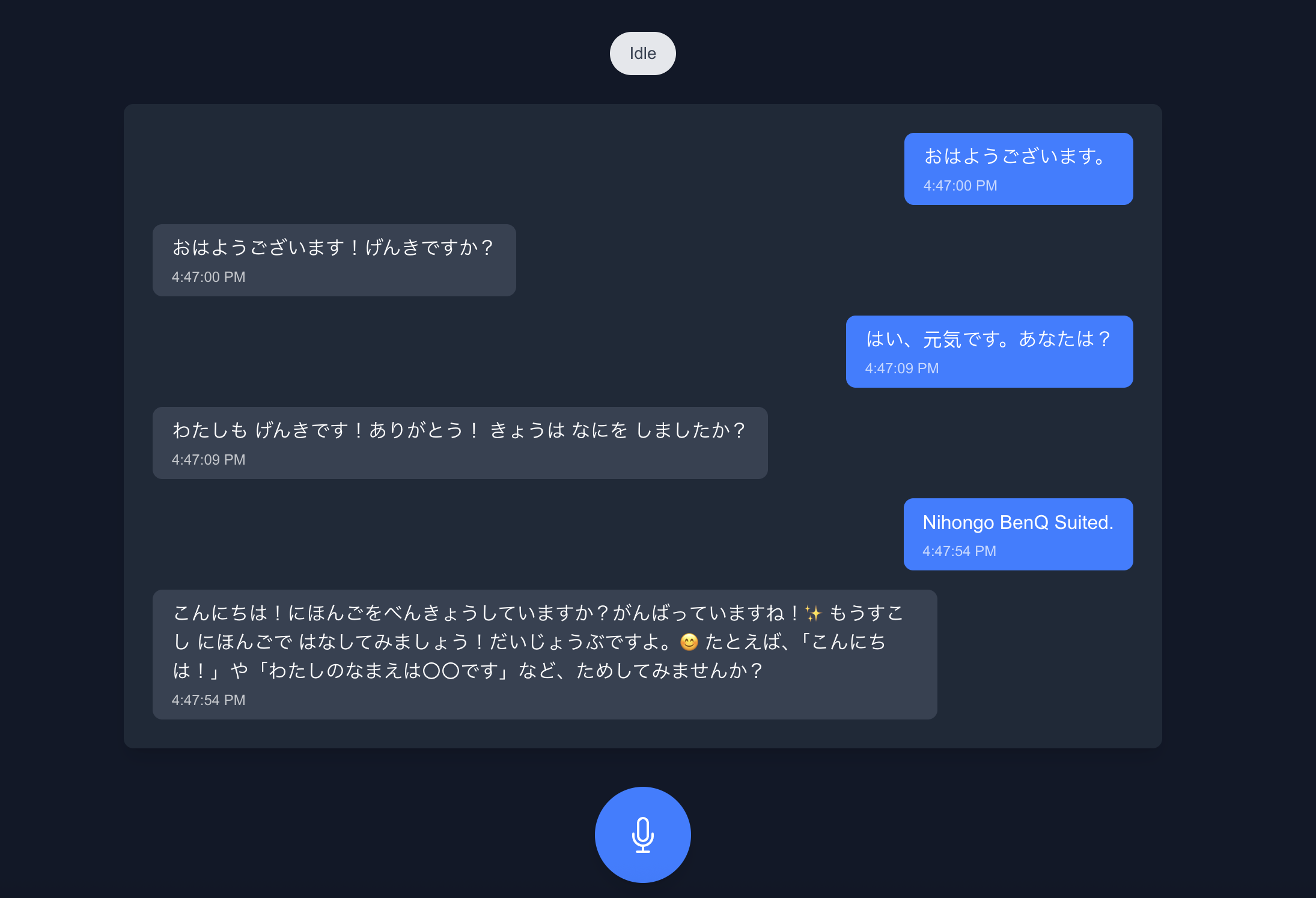
OpenAI’s LLM produced appropriate responses when carefully prompted for N5-level conversation
I’m not entirely sure about this one because I haven’t passed the JLPT N5 yet myself. That said, during testing, it didn’t present anything to me that I felt was complex, so this gets a pass from me. Perhaps with extended sessions, I might see it start breaking out of this constraint, but for now, it’s been solid.
What Didn’t Work
- The agent made many assumptions beyond the initial scope. For example, it started to implement audio streaming, despite it being highlight as a feature what was deprioritized for this POC approach
- The agent would reach for some random npm packages or install outdated versions of popular packages
- Some tasks, like fixing failing tests, required significant manual intervention
Learnings for the next project
This experiment highlighted that there are still gaps in my workflow that need to be addressed to be more effective. Here are some of the key adjustments I’d make for future projects to reduce the need for manual intervention:
TDD (Test-driven development)
- Break down tasks into smaller, independently verifiable chunks. This will help the agent write clearer tests and should make it easier to follow the progress of implementation
- Evolve the standardized process of task execution to ensure that each task/subtask has a test written implemention begins. All the tests in the project should pass before marking the task as complete and moving on
- Sometimes tasks are grouped in a way that makes it difficult to verify changes in the UI until multiple features and large amounts of code are written. Implementing unit and functional tests along the way should afford more peace of mind and prevent the agent from spiralling out of control
Continue to iterate with model choices
- I found that for the vast majority of task implementation, Anthropic’s
claude-3.5-sonnetandclaude-4-sonnetprovide the best value - For generating documentation and fixing tests, more reasoning-based work, OpenAI’s
o3and Google’sgemini-2.5-prowere the better models for the job - Getting better at picking the right models for different classifications of tasks should reduce friction, improve accuracy and speed of development
Better architecture direction
For a POC, loose structure is often fine, but as I plan the MVP-level solution, it’s clear that stronger frontend and backend architecture patterns and code conventions will need to be defined. If the agent follows clear conventions, I’ll have a better understanding of the limitations and trade-offs of the codebase, and it should reduce the time I need to spend reviewing code, as I won’t need to review every single file in detail. Perhaps not the best practice, but for a POC or MVP, I’ll prioritize speed. I’ve seen many stories of vibe-coded apps turning into unmaintainable messes, forcing a total rewrite. I suspect that a lack of clear architectural guidance and coding conventions is an underlying theme in these cases.
Don’t fight the limitations
Cursor prevents agents from interacting with env files, and rightfully so, but this creates an opportunity for the agent to get hung up and spiral. I’ll be creating better rules to yield control back to me to make any env related changes.
Wrapping up
Building this POC has been a fun experiment, and I’m looking forward to pushing the capabilities of Cursor further while building a more robust study tool. Future iterations of this project could include:
- Real-time audio streaming
- Grammar and pronunciation correction
- Learning profiles to track language learning progress
- Situational-based practice (grocery shopping, making reservations, etc.)
- Gradual difficulty increases
Vibe-coding is here to stay, and by combining structured planning and powerful development workflow execution (via tools like Cursor), the possibilities feel endless. It’s reinforced my belief in targeted, minimal experiments as ideal vehicles for rapid learning and iteration, especially when guided by AI. As I refine my approach, I’ll continue to share insights on building practical solutions using AI.